Hugging Face
Hugging Face is a platform that provides tools for building, training and deploying machine learning models. It offers a rich repository of pre-trained models and user-friendly tools, empowering developers and researchers to efficiently create and optimize state-of-the-art ML models for various tasks, particularly in the domain of natural language processing.
Before setting up
Section titled “Before setting up”Before you can connect you need to:
- Create a Hugging Face account.
- Get Access Token:
- Click New token.
- Enter a Name for the token and select the Role from the dropdown.
- Click the Generate a token button.
- Next to generated token, click on Copy token to clipboard icon.
Training or finetuning a model using custom data
Section titled “Training or finetuning a model using custom data”Hugging Face provides a tool for training ML models which can be used to better accommodate your needs. You can read more about AutoTrain here. Once the model is trained on your data, you can use it via Blackbird just like any other model.
Connecting
Section titled “Connecting”- Navigate to apps and search for Hugging Face. If you cannot find Hugging Face then click Add App in the top right corner, select Hugging Face and add the app to your Blackbird environment.
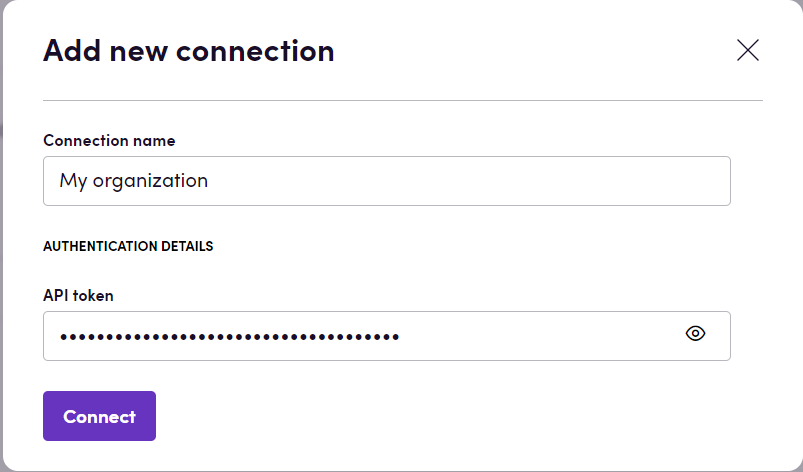
- Click Add Connection.
- Name your connection for future reference e.g. ‘My organization’.
- Fill in the API token obtained in the previous section.
- Click Connect.
- Confirm that the connection has appeared and the status is Connected.
Actions
Section titled “Actions”- Summarize text summarizes longer text into shorter text.
- Answer question answers the question given a context. Context is a text where the answer could be found.
- Answer question with table answers the question given the excel table with .xlsx extension where the answer could be found.
- Classify text performs text classification. Possible labels vary depending on model used. Can be useful for sentiment analysis.
- Classify text according to candidate labels performs text classification and, unlike Classify text action, uses the provided labels for prediction.
- Translate text. Source and target language cannot be specified. It is recommended to use models trained to translate between one language pair. For example, take a look at Helsinki-NLP models.
- Fill mask fills in a hole or holes with missing words and returns text with filled holes. Use mask token to specify the place to be filled. Mask token can differ depending on model used, but the most commonly used tokens are [MASK] or <mask>. You should check the mask token used by specific model on its Hugging Face page.
- Calculate semantic similarity calculates semantic similarity between two texts and returns similarity score in the range from 0 to 1.
- Generate text continues text from a prompt.
- Chat performs conversational task. To give a context, you can specify past user inputs and previously generated responses which should have the same lengths.
- Classify tokens performs token classification. Usually used for keywords extraction or grammatical sentence parsing. You can check model usage and entity groups (tags) on respective model’s Hugging face page.
- Generate embedding generates text embedding - a list of floating point numbers that captures semantic information about the text that it represents. Embeddings can be used to store data in vector databases (like Pinecone).
- Create transcription generates a transcription given an audio file (Flac, Wav, Mp3, Ogg etc.).
- Classify audio performs audio classification. Possible labels vary depending on model used.
- Generate image generates image given text description of image.
- Classify image performs image classification. Possible labels vary depending on model used.
- Convert image to text generates text description for given image.
- Answer question based on image performs visual question answering based on given image.
Note: many actions have optional input parameter Use cache. By default, it is set to true, meaning that if model has already seen the same input, it will return previously obtained result. You can use it to make sure you get deterministic results. If you don’t want the model to return exactly the same results for queries it has seen before, you can set Use cache to false.
Missing features
Section titled “Missing features”In the future we can add actions for:
- Image detection
- Image segmentation
Let us know if you’re interested!